



个人用户玩转Stable Diffusion的GPU配置推荐
随着人工智能(Artificial Intelligence) 的快速发展和在各个领域的深度使用,给全世界带来了新的发展机遇,对于企业和个人用户,快速的掌握应用AI技术能极大的促进企业生产效率和满足当下市场的人才技术需求,但是由于AI应用的必要硬件门槛GPU显卡对于大部分用户来说接触认知较少,同时市场对于显卡的使用需求越来越强,因此帮助个人用户了解自身需求和选择需要的设备是推出本篇显卡和AIPC配置推荐的首要任务。
生成式 AI 模型和技术介绍
生成式模型是一类机器学习模型,其目标是能够让AI模型在一些简单的提示下,生产出高质量的内容。比如去年开始大火的ChatGPT,以及今天主要介绍的Stable Diffusion,都属于生成式AI模型。
生成式模型在许多任务和领域中具有广泛的应用。例如,在自然语言处理领域,生成式模型可以用于文本生成、机器翻译和对话系统等任务。在计算机视觉领域,生成式模型可以用于图像生成、图像修复和图像超分辨率等任务。此外,生成式模型还可以应用于音频合成、视频生成和艺术创作等领域。
训练一个可靠的生成式模型通常需要上亿的参数与海量的训练数据。随着互联网的发展和技术的进步,我们可以获得大规模的数据集,这为训练更复杂、更准确的模型提供了基础。同时,高性能的计算设备如图形处理器(GPU)和领域专用芯片(如TPU)的发展,使得训练和推理大规模的生成式模型变得可能。
图像生成式模型
图像生成式模型能够在无提示,或者简单提示的情况下,生成高质量、以假乱真的图片。图像生成技术发展了很多年,有生成式对抗网络(GAN)、变分编码器(VAE)等多个类别,而在去年潜在扩散模型(Latent Diffusion Model)由于其划时代的生图质量,正式让图像生成式模型走进了大众的视野。
Stable Diffusion Model是Stability AI和Laion等公司共同研发的一个基于LDM的AI生图模型,因为稳定的出图效果和出图质量,以及公开的源码,和可微调的优势在开源后短时间内引起了世界范围内的AI生图热潮。
Stable Diffusion v1.5
Stable Diffusion v1.5(下面简称SD 1.5)是Stability AI公司2022年推出的图像生成式模型,也是第一代引发广泛关注的SD模型。用户可以通过输入文本提示词,生产一张符合文本描述的图片。比如输入提示词:“aurora”就能生成一张极光的图。

Stable Diffusion XL
Stable Diffusion XL v1.0(下面简称SDXL)是Stability AI公司在2023年推出的图像生成式模型。在SD 1.5的基础上,SDXL大幅增加了网络参数量(U-Net部分由8亿增加到25亿),新增了更强大的文本编码器,而带来的结果则是,SDXL全方位的能力得到了质的提升。不同于SD 1.5最高只能胜任768768图像的生成,SDXL可以轻松生成10241024规格的图片。而U-Net、文本编码器的提升使得SDXL模型在文本控制力、生图质量上都有显著的提升。
而除开SD 1.5和SDXL最起初的文生图的能力,它们的可扩展性才是它得以被广泛传播,最终形成一个庞大的AI社区的原因。
Stable Diffusion 3

Stabel Diffusion 3是Stability AI公司在研的最新文生图大模型,采用了和OpenAI视频大模型Sora类似的Diffusion-Transformer架构,质量水平对标OpenAI的DALLE·3和Midjourney V6,画面质量水平和文本一致性方面比较之前的模型均有着巨大的进步,有多个数据大小的版本选择。


图像生成技术介绍
LoRA
LoRA全称低秩适应性网络(Low-Rank Adaptation),是诞生于大语言模型的技术。而在Stable Diffusion社区,LoRA焕发了新的生命力。LoRA可以理解为SD模型的插件,以极小的模型参数量和少量的训练样本,就能微调出特定的任务/画风,实现定制化需求。下图展示了吐司平台上的创作者训练的三个LoRA,用户可以根据不同的生图需求,在社区海量的内容中找到合适的LoRA,甚至可以训练出自己的专属LoRA。



ControlNet
ControlNet也是SD模型的外置网络,可以通过线稿、深度图、骨架姿态等方法,实现对生图的精确控制。



TensorRT
NVIDIA TensorRT 是一款用于高性能深度学习推理的 SDK,包含深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。相比学术界常用的 PyTorch、TensorFlow 框架,TensorRT 可以让 NVIDIA 显卡在 AI 模型推理时获得显著的速度提升而不损失结果质量。
图像生成任务的硬件性能测试
吐司作为世界领先的模型平台和社区,此次与英伟达合作,测试了Stable Diffusion模型在英伟达 RTX 40 系显卡上的表现。测试覆盖了 RTX 40 系的全部桌面级显卡。
NVIDIA RTX 桌面级显卡在 Stable Diffusion 图像生成任务上的表现

测试环境:
CPU: 英特尔 Core i5-13600KF
内存: 芝奇 DDR5 6400MHz 16GB x 2
主板: 技嘉 Z790M AORUS ELITE AX
硬盘: 三星 PM9A1 2TB M.2
电源: 振华 G850
操作系统: Windows 11 23H2
SD 1.5 推理性能 UL Procyon Benchmark
SD1.5是当前最流行的SD基座版本,也是现在模型社区的主要微调训练版本,可在最低 6GB 显存上进行推理运行。
测试参数:
采样器:DDIMScheduler
生图分辨率:512*512
生图步数:100
生图数量:16
batch_size:4
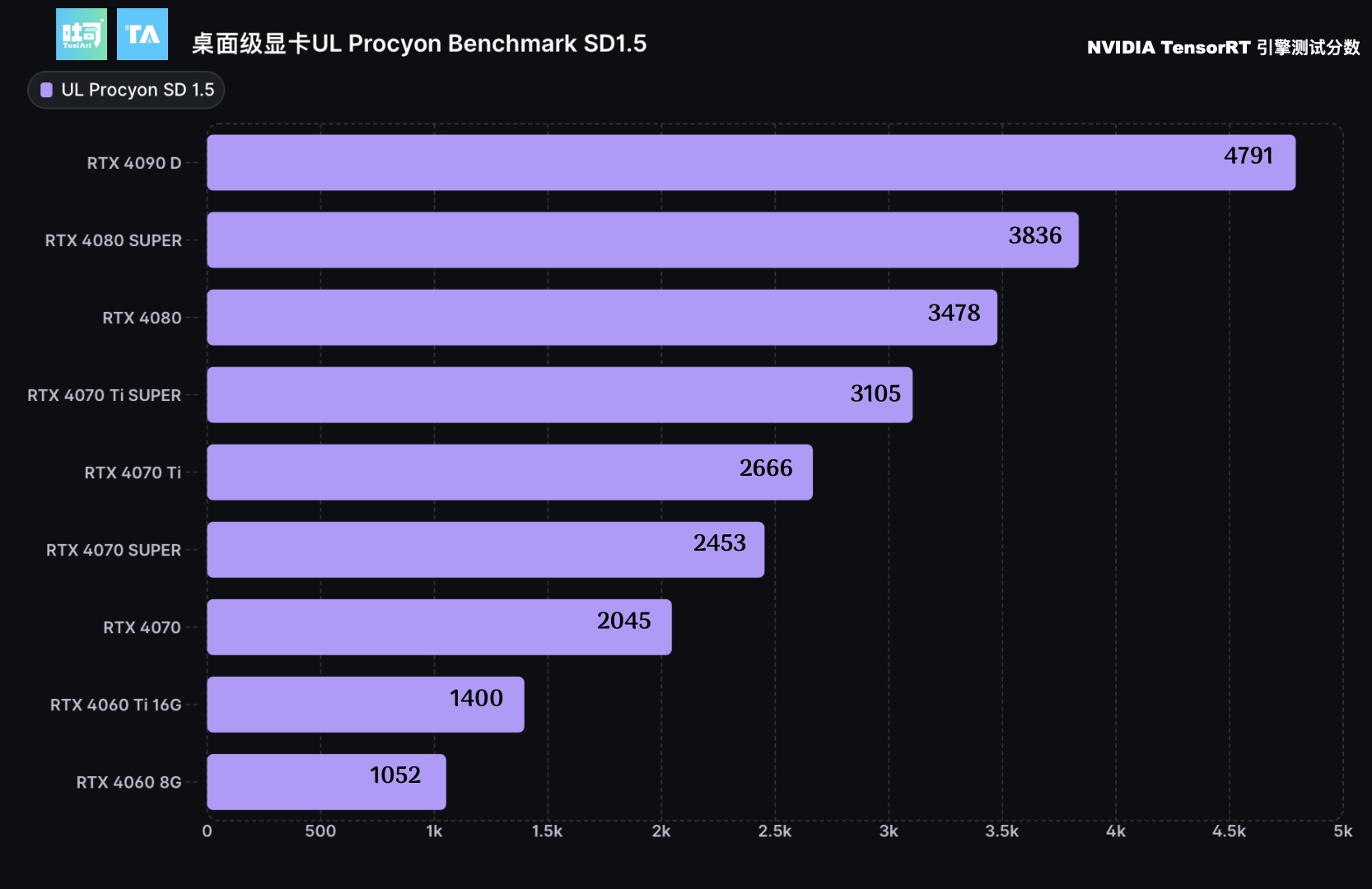
SD 1.5 推理性能吐司测试(TensorRT启用前后对比)
采样器:DPM++ 2M
生图分辨率:512*512
生图步数:50
生图数量:20
batch_size:1
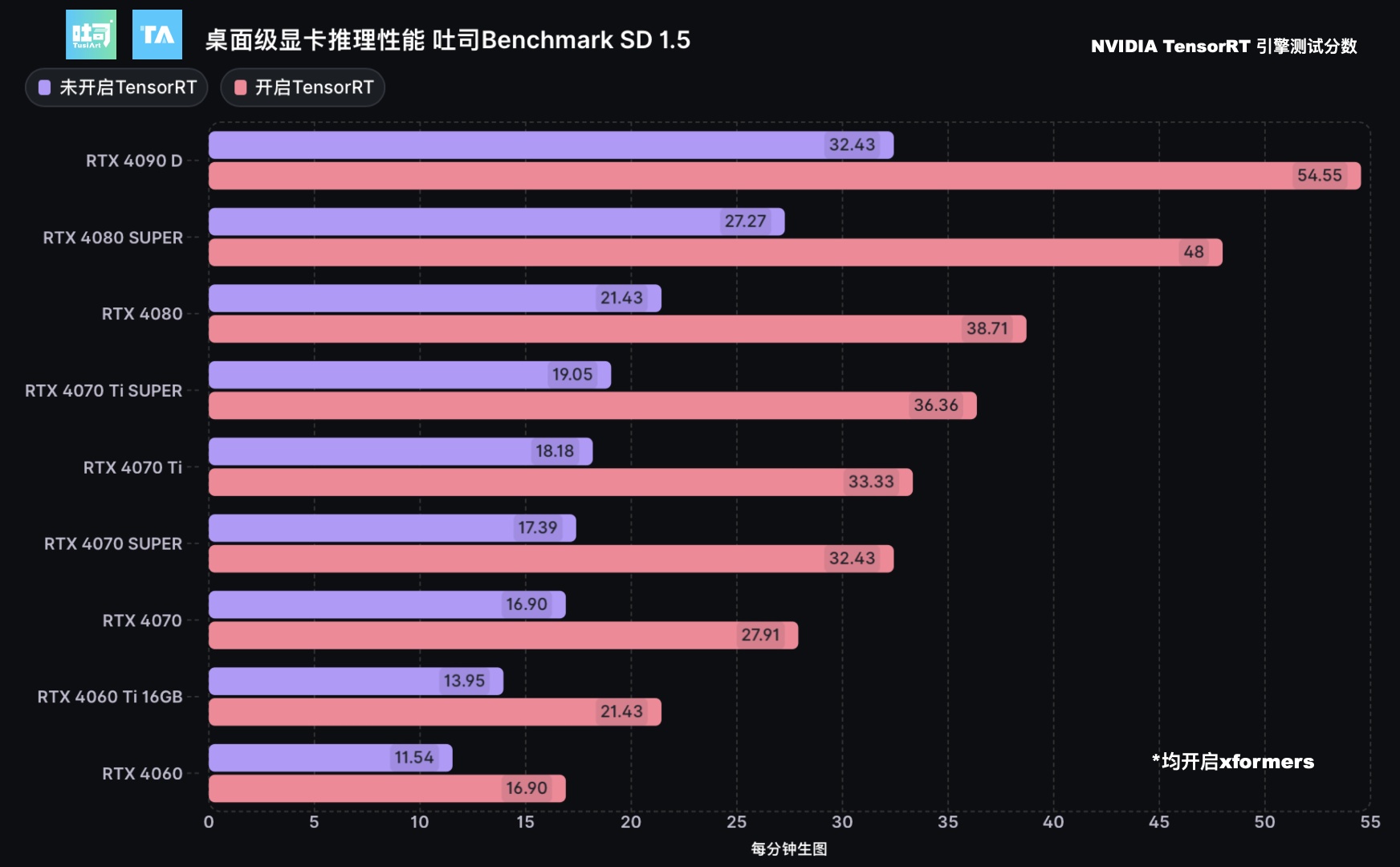
根据吐司平台的测试结果,在NVIDIA TensorRT的加持下,英伟达RTX40系显卡可以实现最高翻倍的生图性能提升。
SDXL 推理性能 UL Procyon Benchmark
采样器:DDIMScheduler
生图分辨率:1024*1024
生图步数:100
生图数量:16
batch_size:1
SDXL模型推理需要至少10GB显存,故 RTX 4060 8GB 因显存不足无法完成测试。
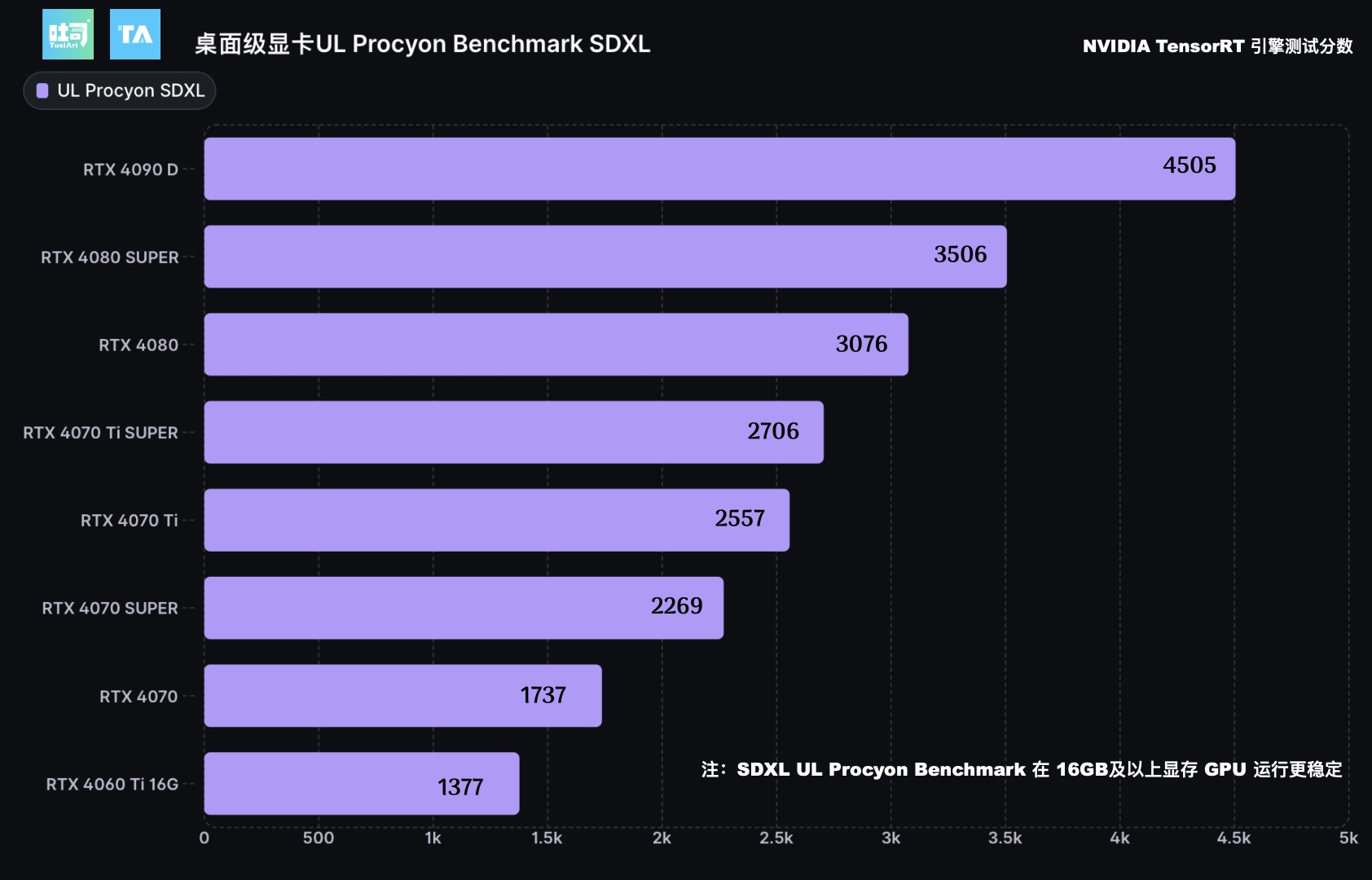
SDXL 推理性能吐司测试(TensorRT启用前后对比)
采样器:DPM++ 2M
生图分辨率:1024*1024
生图步数:50
生图数量:20
batch_size:1
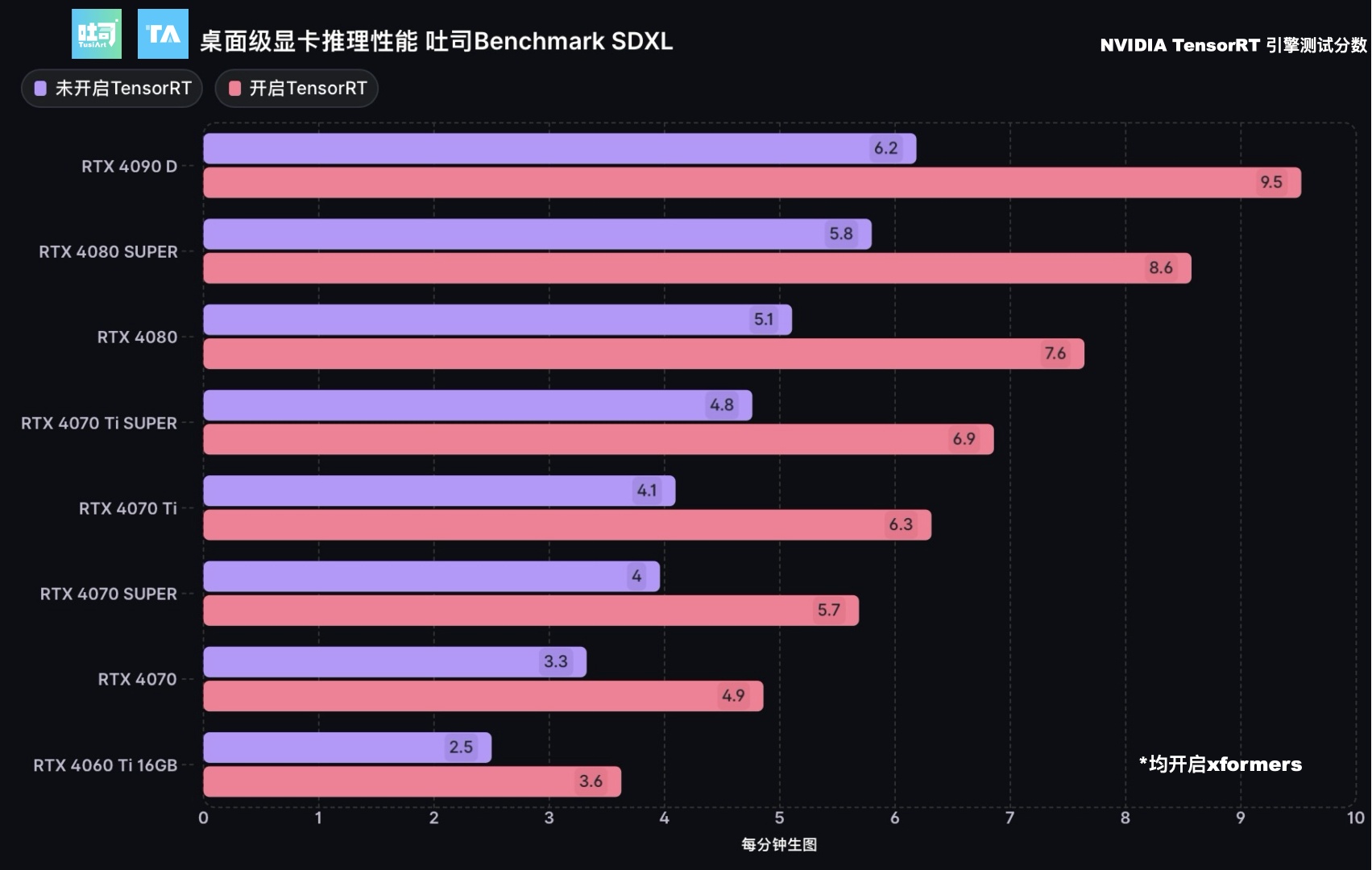
在SDXL生图任务上,也几乎都能达到50%以上的性能提升
NVIDIA RTX AIPC 在 Stable Diffusion 图像生成任务上的表现
AIPC的SD图像生成能力测试中,我们测试了搭载 GeForce RTX 4050 - RTX 4090 笔记本电脑 GPU 的 ASUS华硕 / ROG 的 RTX AIPC。

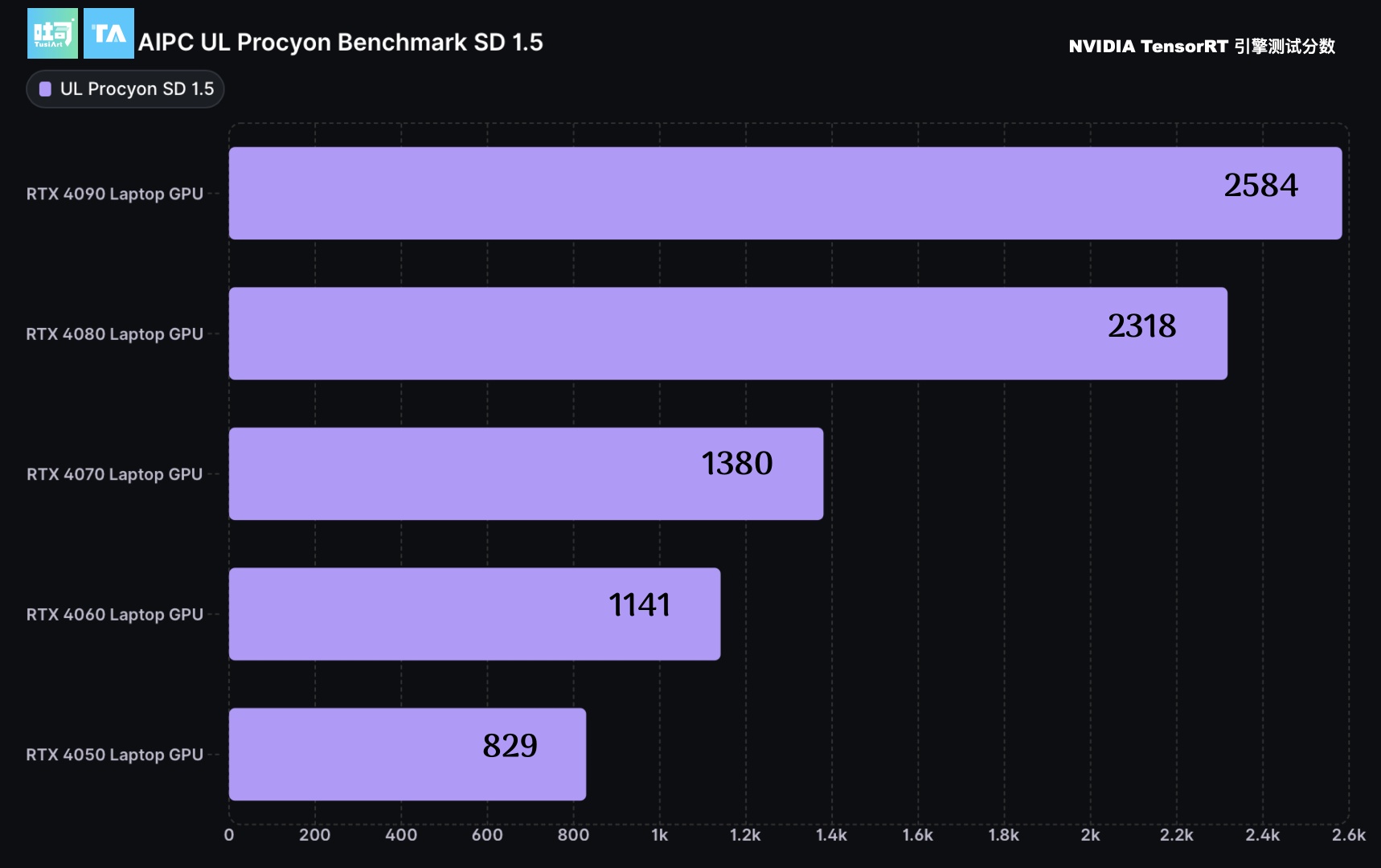
SD 1.5 推理性能 UL Procyon Benchmark
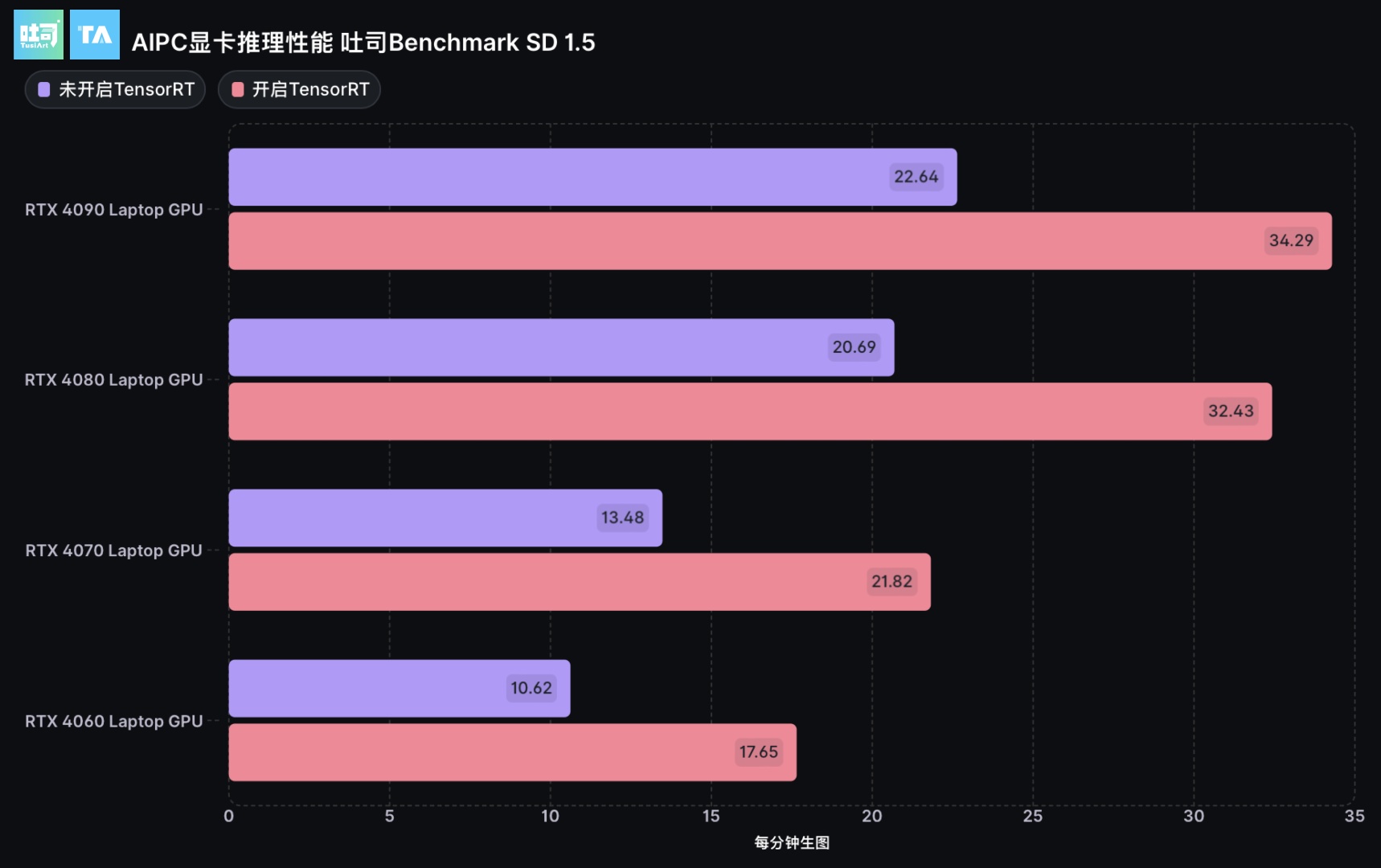
SD1.5 推理性能吐司测试(TensorRT启用前后对比)
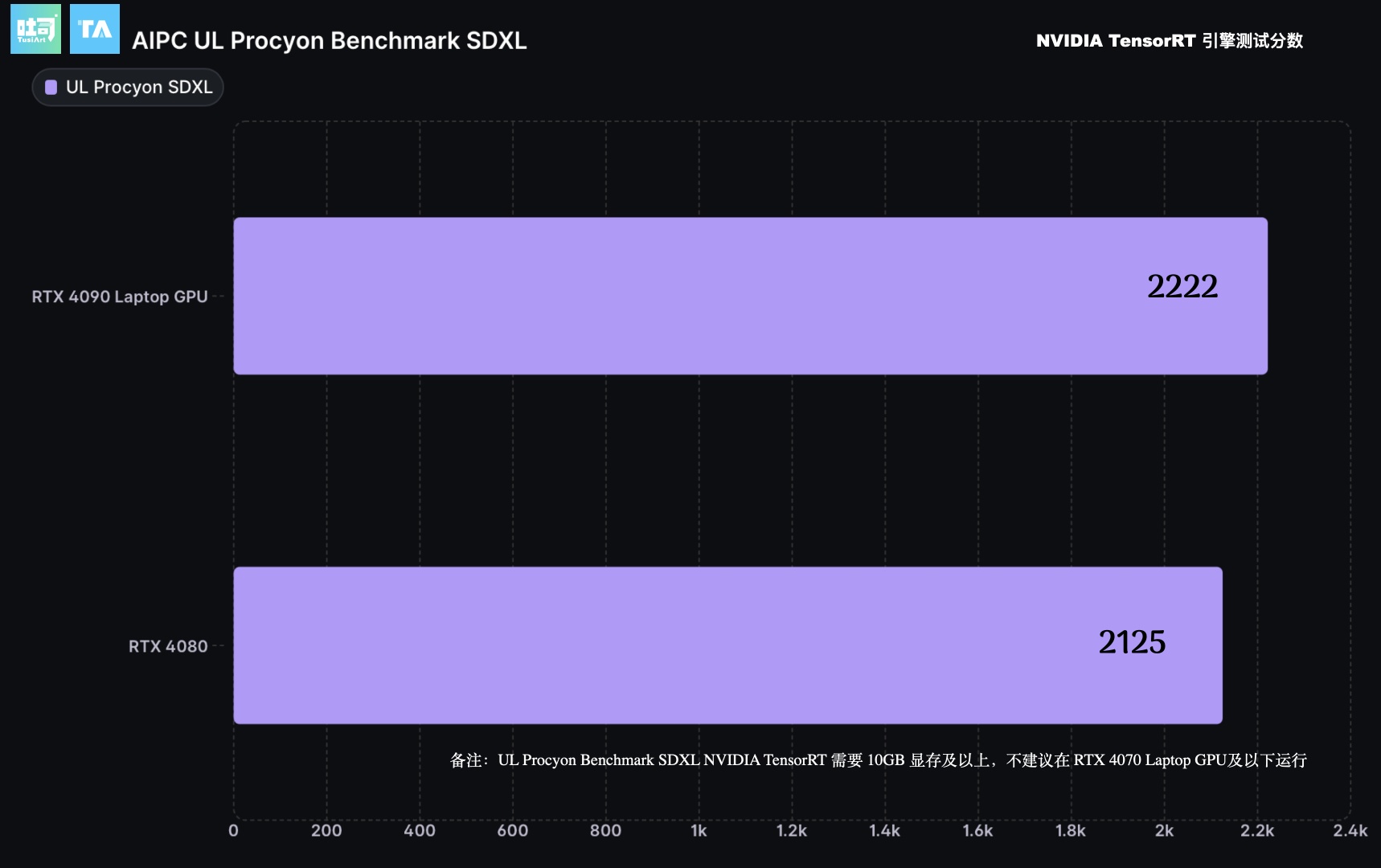
SDXL 推理性能 UL Procyon Benchmark
SDXL模型推理需要至少10GB显存,故 RTX 4050 Laptop, RTX 4060 Laptop, RTX 4070 Laptop 因显存不足无法完成测试。
SDXL 推理性能吐司测试(TensorRT启用前后对比)
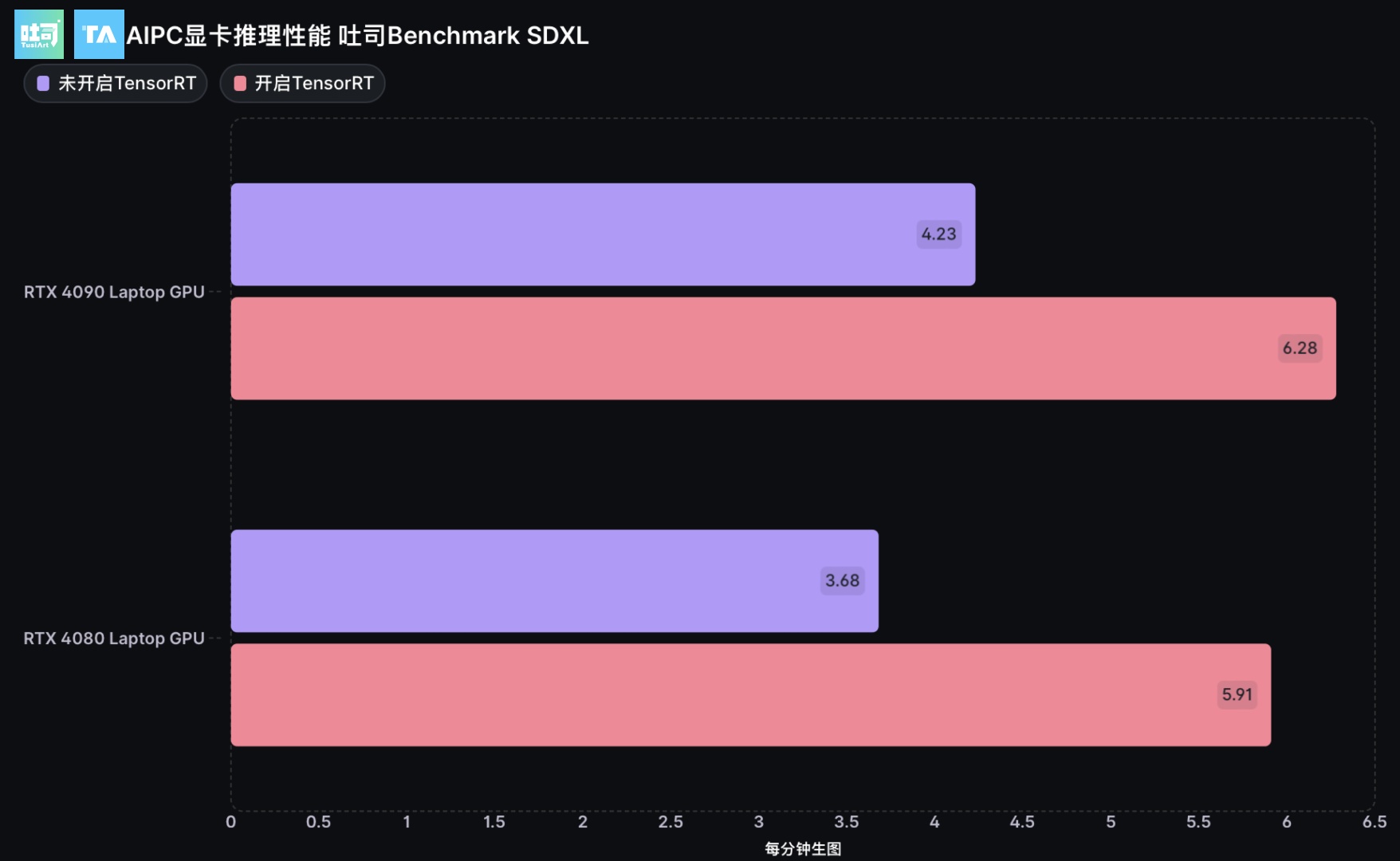
NVIDIA RTX 40 系列 Laptop GPU在笔记本上依旧有亮眼的表现,且兼具便携、低功耗等特点,更适合有通勤需求的用户
NVIDIA RTX AIPC 对比 Intel Arc Graphics
测试工具:UL Procyon Benchmark
采样器:DDIMScheduler
生图分辨率:512*512
生图步数:100
生图数量:16
batch_size:4
对比硬件型号:
- RTX 4090 Laptop GPU
- Intel Core Ultra 9 185H
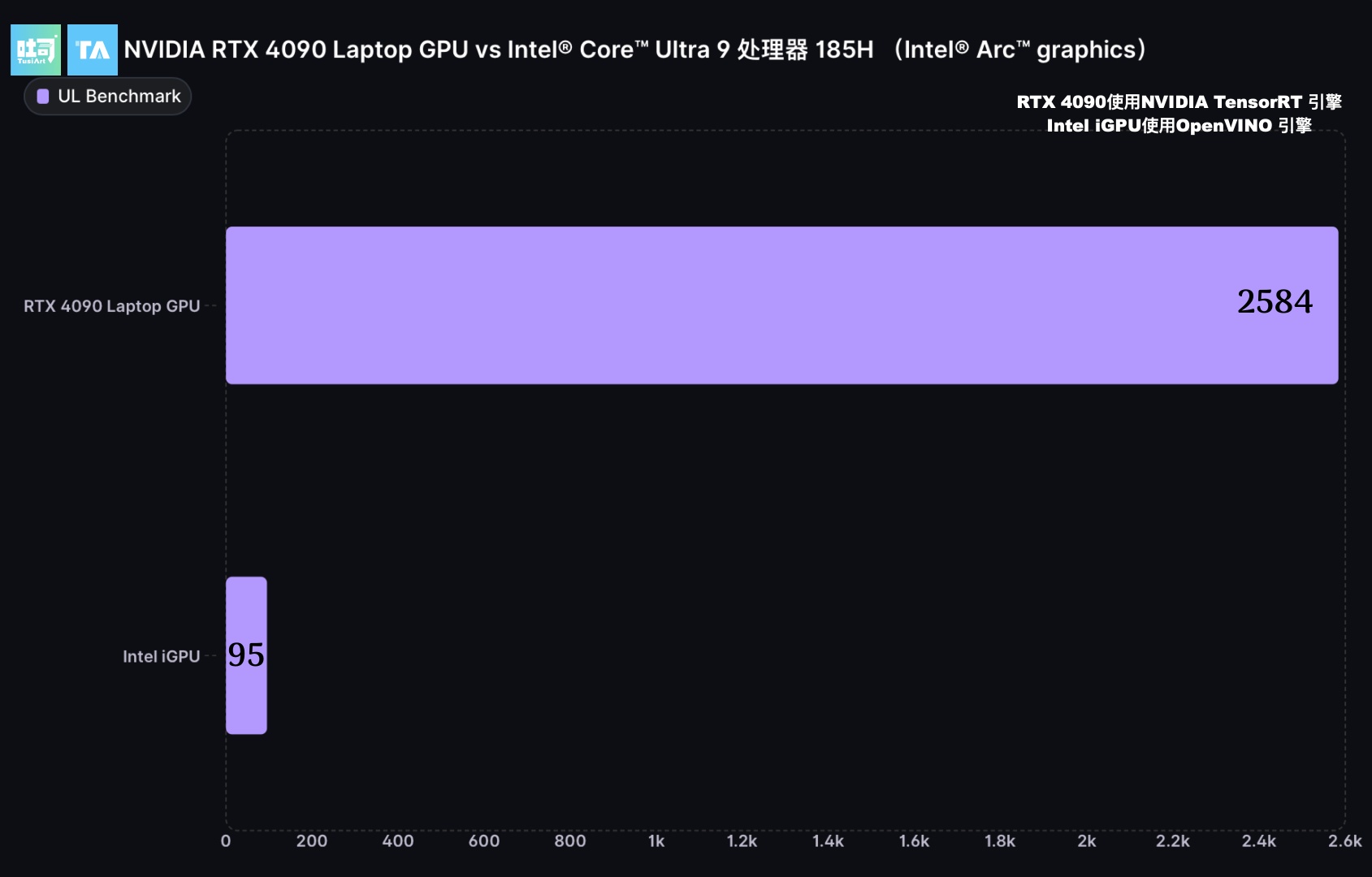
图像生成任务所需的硬件配置总结
| 模型 | 参数量 | 独立显卡 | AIPC |
|---|---|---|---|
| SD 1.5 | 9亿 | 最低:GeForce RTX 4060 8GB推荐:GeForce RTX 4070 12GB 及以上 | 最低:RTX 4050 Laptop 6GB推荐:RTX 4080 Laptop 12GB 及以上 |
| SDXL 1.0 | 35亿 | 最低:GeForce RTX 4070 12GB推荐:GeForce RTX 4070 SUPER 12GB 及以上 | 最低:RTX 4080 Laptop 12GB推荐:RTX 4090 Laptop 16GB |
模型微调训练任务的硬件性能测试
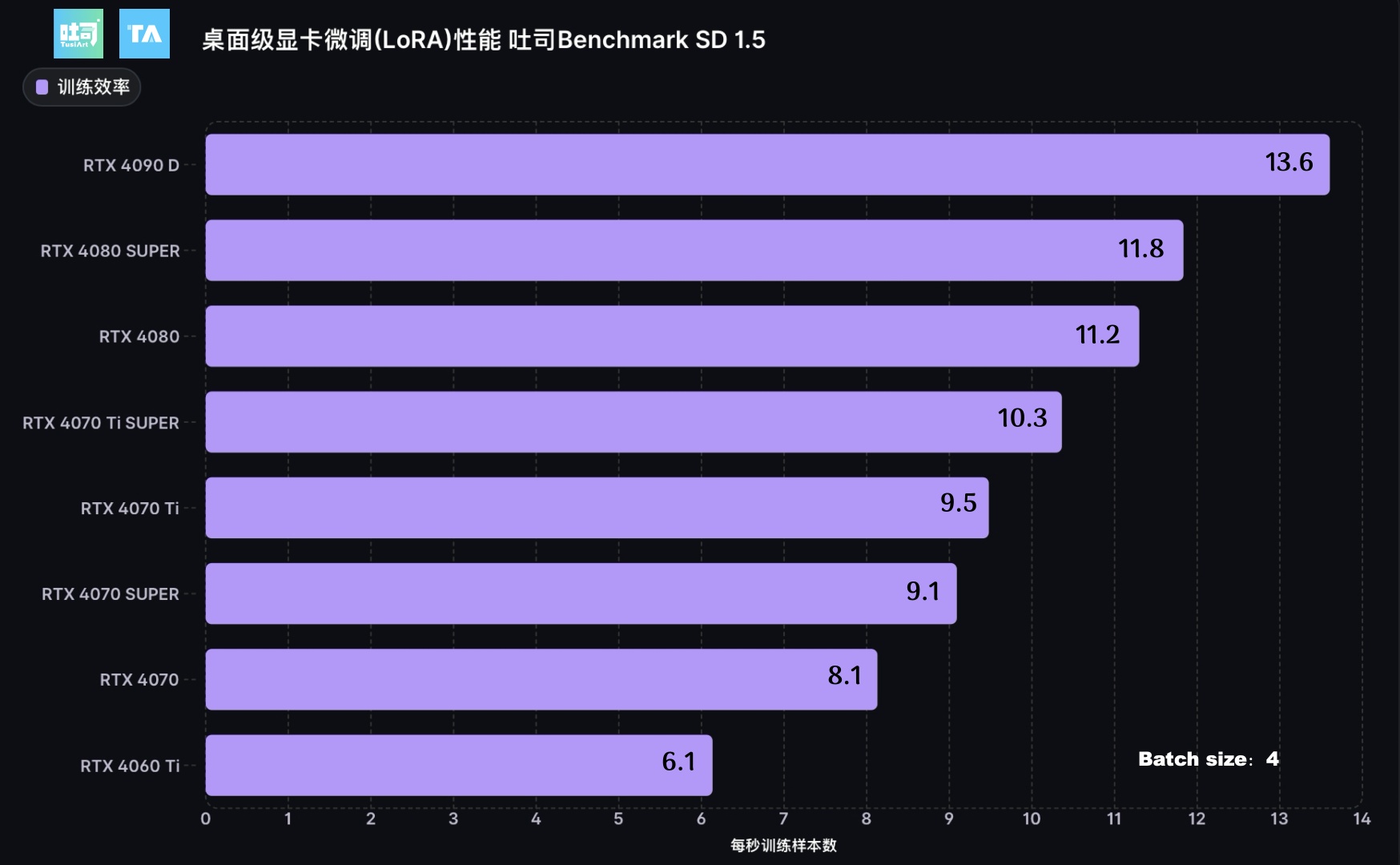
NVIDIA RTX 显卡 在 SD 1.5 LoRA训练任务的测试
底模:Anything V5
LoRA rank: 32
分辨率:512*512
样本量:1000
Batch size: 4
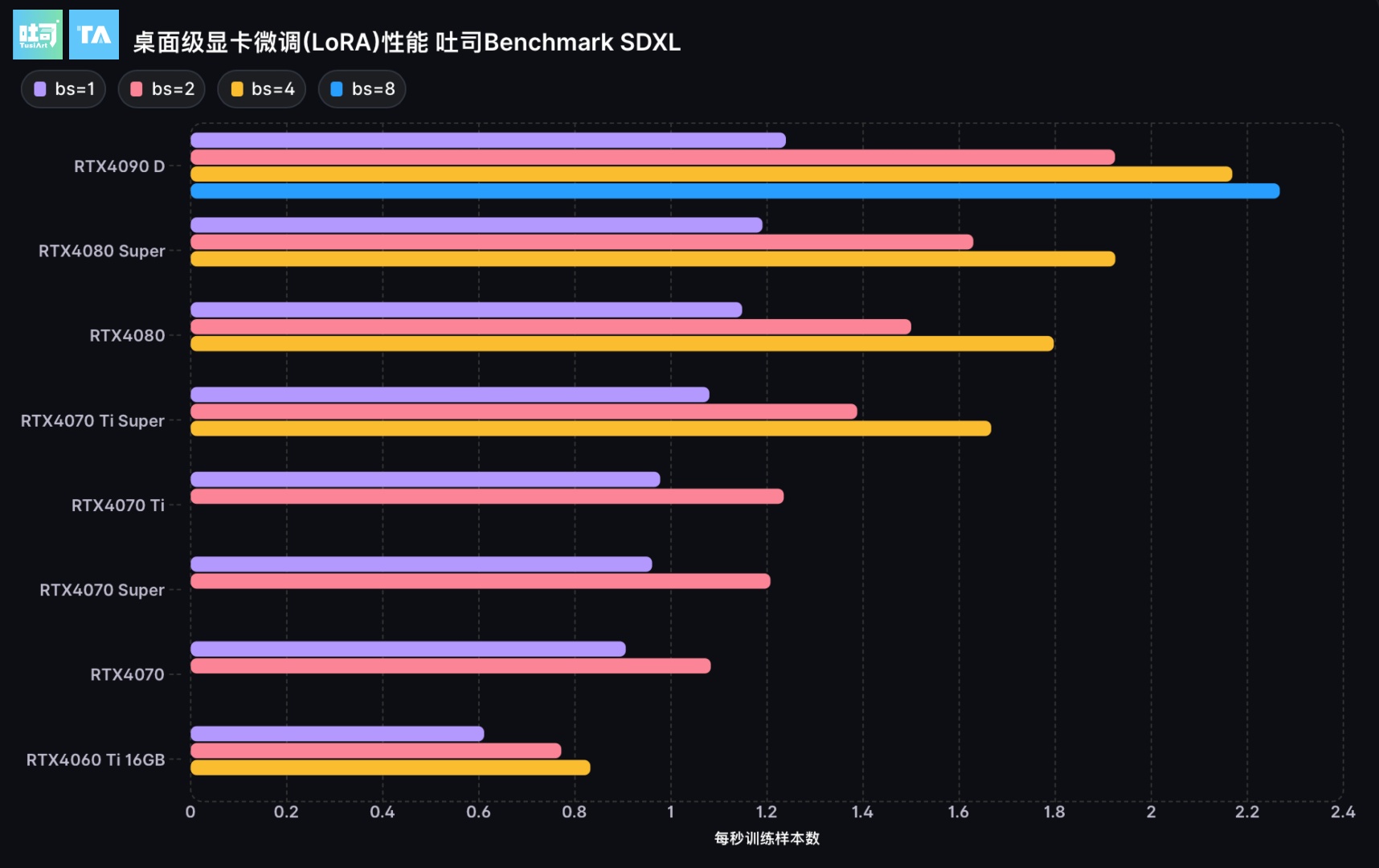
NVIDIA RTX 显卡 在 SDXL LoRA训练任务的测试
在模型微调任务中,CPU性能、显存和算力都有可能成为瓶颈。
由于SDXL LoRA训练需要至少10GB的显存,RTX 4060 8GB 因显存不足而无法进行 SDXL LoRA训练,12GB显存及以下的显卡无法完成batch_size=4的测试,16GB显存及以下的显卡无法完成batch_size=8的测试。
RTX 4090 D拥有高达24GB的显存和14592个CUDA核心,在计算密集型任务上有额外优势,所以本次吐司在SDXL微调任务上将batch size提升到了8,将RTX 4090 D的性能发挥到极致,训练效率也相比batch size=1时提升了将近100%
底模:Anything XL
LoRA rank: 32
分辨率:1024*1024
样本量: 1000
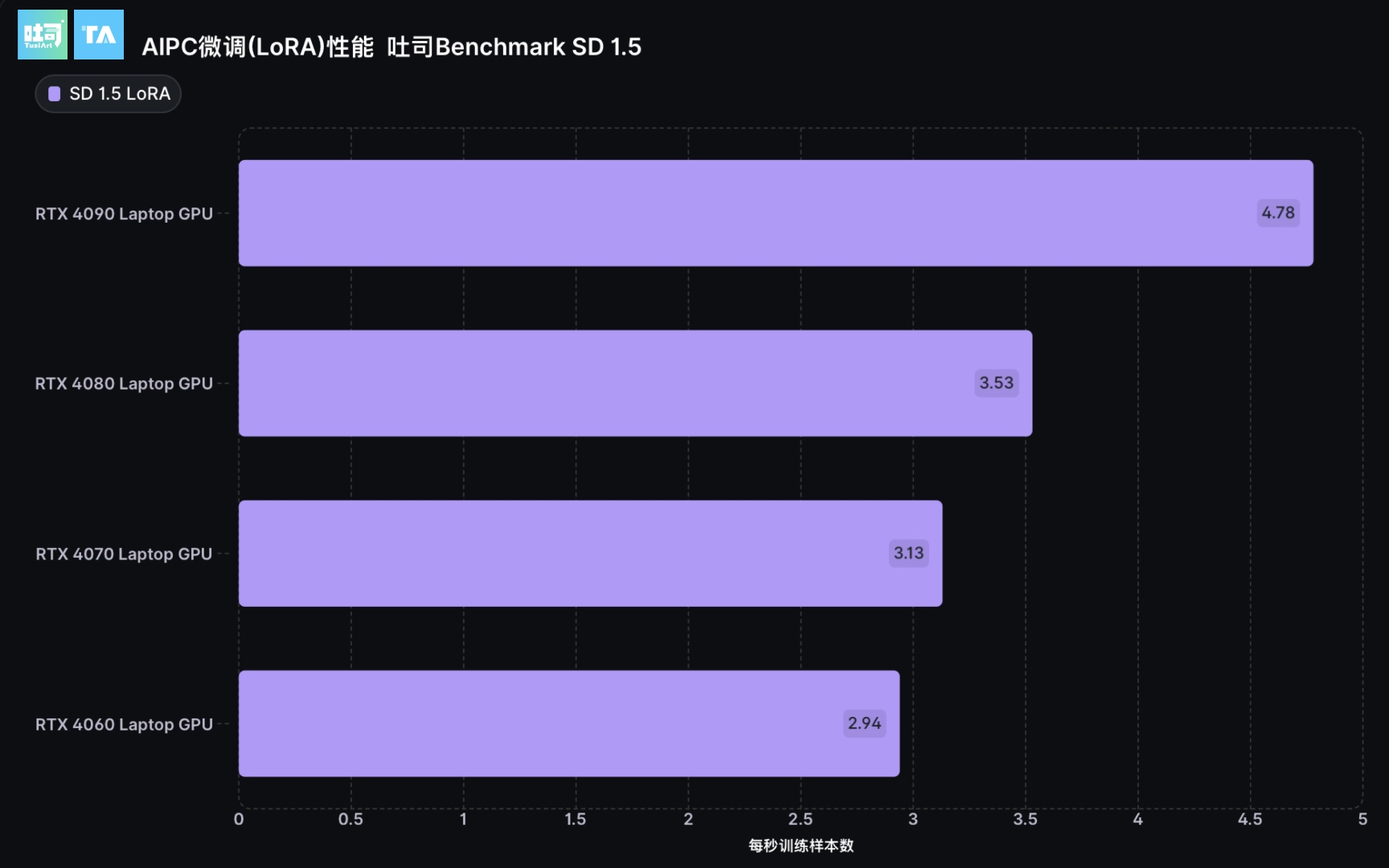
NVIDIA RTX AIPC 在 SD 1.5 LoRA 训练任务的测试
由于SD1.5 LoRA训练需要至少8GB的显存,RTX 4050 Laptop 因显存不足而无法进行SD1.5 LoRA训练。
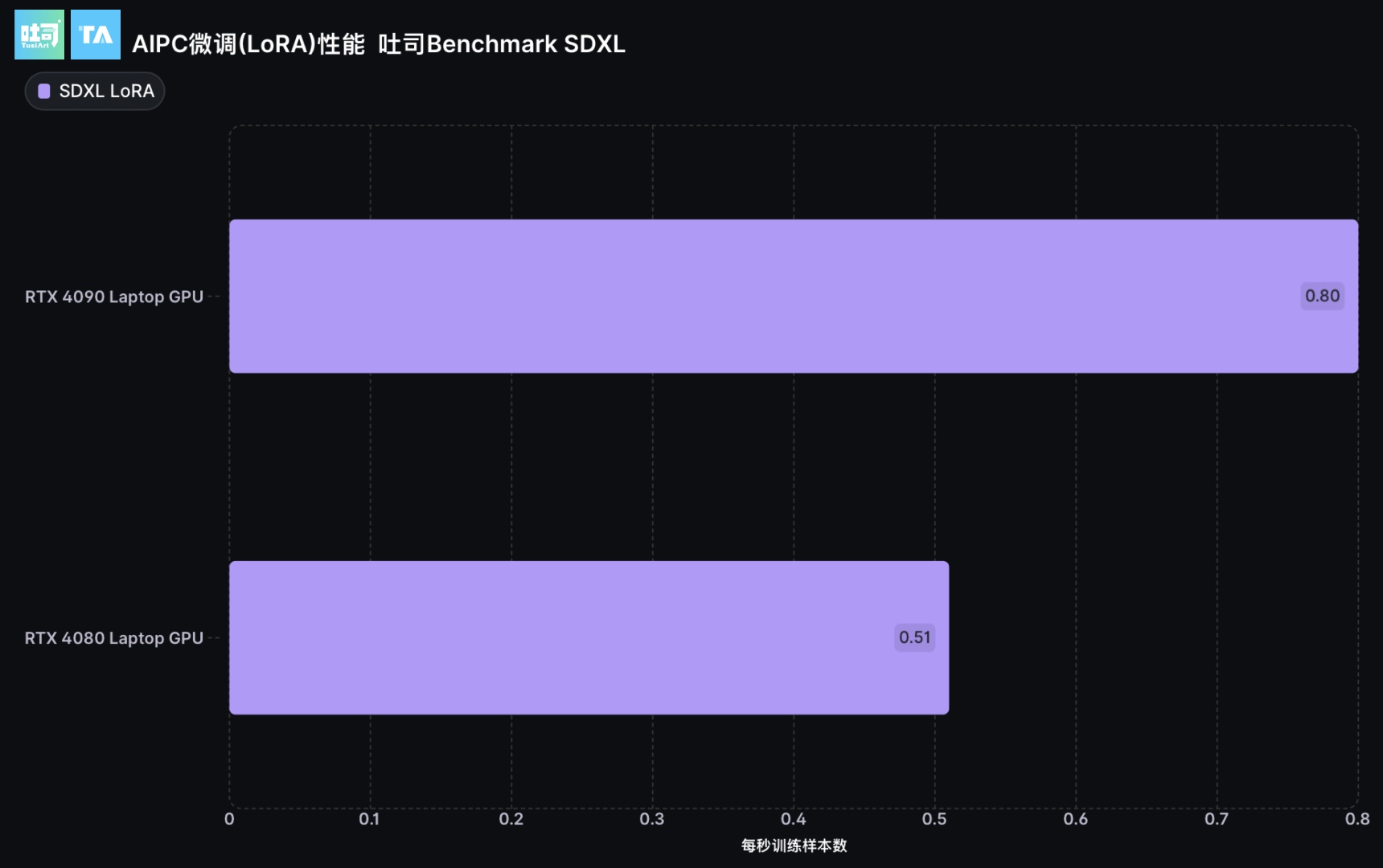
NVIDIA RTX AIPC 在 SDXL LoRA训练任务的测试
由于SDXL LoRA训练需要至少10GB的显存,RTX 4050 Laptop, RTX 4060 Laptop, RTX 4070 Laptop 因显存不足而无法进行SDXL LoRA训练。
模型微调训练所需的硬件配置总结
| 模型 | 参数量 | 独立显卡 | AIPC |
|---|---|---|---|
| SD 1.5 | 9亿 | GeForce RTX 4070 12GB | RTX 4060 Laptop 8GB |
| SDXL 1.0 | 35亿 | GeForce RTX 4070Ti SUPER 16G | RTX 4090 Laptop 16GB |
结语
人工智能技术曾经一度是大中型企业的私有工具,有着极高的学习与应用门槛。但在过去的一年中,随着StableDiffusion等生成式AI应用的火爆,我们欣喜地发现,我们已经能在每一台个人电脑上部署生成式AI模型,每一个用户都能够根据自己的喜好,微调出属于自己的大模型。我们衷心地期待,随着大模型技术和硬件加速器的蓬勃发展,AI大模型可以成为每个人的生产力工具,能够为每个人的工作和娱乐定义新的范式。
附录
测试显卡型号一览
感谢英伟达、影驰、七彩虹公司为我们提供测试显卡:
- 七彩虹 iGame GeForce RTX 4090 D Advanced 24GB
- GeForce RTX 4080 SUPER 16GB Founders Edition
- GeForce RTX 4080 16GB Founders Edition
- 影驰 GeForce RTX 4070Ti SUPER 大将 OC 16GB
- GeForce RTX 4070Ti 12GB Founders Edition
- GeForce RTX 4070 SUPER 12GB Founders Edition
- GeForce RTX 4070 12GB Founders Edition
- 七彩虹 iGame GeForce RTX 4060Ti 16GB
- GeForce RTX 4060 8GB Founders Edition
测试AIPC型号一览
感谢华硕公司为我们提供测试AIPC:
- RTX 4090 Laptop 16GB ROG 枪神8 Plus 超竞版

- RTX 4080 Laptop 12GB ROG 魔霸7 Plus超能版

- RTX 4070 Laptop 8GB ROG 枪神8

- RTX 4060 Laptop 8GB ROG 魔霸新锐2024

- RTX 4050 Laptop 6GB 华硕天选4锐龙版

个人用户玩转Stable Diffusion的GPU配置推荐
随着人工智能(Artificial Intelligence) 的快速发展和在各个领域的深度使用,给全世界带来了新的发展机遇,对于企业和个人用户,快速的掌握应用AI技术能极大的促进企业生产效率和满足当下市场的人才技术需求,但是由于AI应用的必要硬件门槛GPU显卡对于大部分用户来说接触认知较少,同时市场对于显卡的使用需求越来越强,因此帮助个人用户了解自身需求和选择需要的设备是推出本篇显卡和AIPC配置推荐的首要任务。
生成式 AI 模型和技术介绍
生成式模型是一类机器学习模型,其目标是能够让AI模型在一些简单的提示下,生产出高质量的内容。比如去年开始大火的ChatGPT,以及今天主要介绍的Stable Diffusion,都属于生成式AI模型。
生成式模型在许多任务和领域中具有广泛的应用。例如,在自然语言处理领域,生成式模型可以用于文本生成、机器翻译和对话系统等任务。在计算机视觉领域,生成式模型可以用于图像生成、图像修复和图像超分辨率等任务。此外,生成式模型还可以应用于音频合成、视频生成和艺术创作等领域。
训练一个可靠的生成式模型通常需要上亿的参数与海量的训练数据。随着互联网的发展和技术的进步,我们可以获得大规模的数据集,这为训练更复杂、更准确的模型提供了基础。同时,高性能的计算设备如图形处理器(GPU)和领域专用芯片(如TPU)的发展,使得训练和推理大规模的生成式模型变得可能。
图像生成式模型
图像生成式模型能够在无提示,或者简单提示的情况下,生成高质量、以假乱真的图片。图像生成技术发展了很多年,有生成式对抗网络(GAN)、变分编码器(VAE)等多个类别,而在去年潜在扩散模型(Latent Diffusion Model)由于其划时代的生图质量,正式让图像生成式模型走进了大众的视野。
Stable Diffusion Model是Stability AI和Laion等公司共同研发的一个基于LDM的AI生图模型,因为稳定的出图效果和出图质量,以及公开的源码,和可微调的优势在开源后短时间内引起了世界范围内的AI生图热潮。
Stable Diffusion v1.5
Stable Diffusion v1.5(下面简称SD 1.5)是Stability AI公司2022年推出的图像生成式模型,也是第一代引发广泛关注的SD模型。用户可以通过输入文本提示词,生产一张符合文本描述的图片。比如输入提示词:“aurora”就能生成一张极光的图。
Stable Diffusion XL
Stable Diffusion XL v1.0(下面简称SDXL)是Stability AI公司在2023年推出的图像生成式模型。在SD 1.5的基础上,SDXL大幅增加了网络参数量(U-Net部分由8亿增加到25亿),新增了更强大的文本编码器,而带来的结果则是,SDXL全方位的能力得到了质的提升。不同于SD 1.5最高只能胜任768768图像的生成,SDXL可以轻松生成10241024规格的图片。而U-Net、文本编码器的提升使得SDXL模型在文本控制力、生图质量上都有显著的提升。
而除开SD 1.5和SDXL最起初的文生图的能力,它们的可扩展性才是它得以被广泛传播,最终形成一个庞大的AI社区的原因。
Stable Diffusion 3
Stabel Diffusion 3是Stability AI公司在研的最新文生图大模型,采用了和OpenAI视频大模型Sora类似的Diffusion-Transformer架构,质量水平对标OpenAI的DALLE·3和Midjourney V6,画面质量水平和文本一致性方面比较之前的模型均有着巨大的进步,有多个数据大小的版本选择。
图像生成技术介绍
LoRA
LoRA全称低秩适应性网络(Low-Rank Adaptation),是诞生于大语言模型的技术。而在Stable Diffusion社区,LoRA焕发了新的生命力。LoRA可以理解为SD模型的插件,以极小的模型参数量和少量的训练样本,就能微调出特定的任务/画风,实现定制化需求。下图展示了吐司平台上的创作者训练的三个LoRA,用户可以根据不同的生图需求,在社区海量的内容中找到合适的LoRA,甚至可以训练出自己的专属LoRA。
ControlNet
ControlNet也是SD模型的外置网络,可以通过线稿、深度图、骨架姿态等方法,实现对生图的精确控制。
TensorRT
NVIDIA TensorRT 是一款用于高性能深度学习推理的 SDK,包含深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。相比学术界常用的 PyTorch、TensorFlow 框架,TensorRT 可以让 NVIDIA 显卡在 AI 模型推理时获得显著的速度提升而不损失结果质量。
图像生成任务的硬件性能测试
吐司作为世界领先的模型平台和社区,此次与英伟达合作,测试了Stable Diffusion模型在英伟达 RTX 40 系显卡上的表现。测试覆盖了 RTX 40 系的全部桌面级显卡。
NVIDIA RTX 桌面级显卡在 Stable Diffusion 图像生成任务上的表现
测试环境:
CPU: 英特尔 Core i5-13600KF
内存: 芝奇 DDR5 6400MHz 16GB x 2
主板: 技嘉 Z790M AORUS ELITE AX
硬盘: 三星 PM9A1 2TB M.2
电源: 振华 G850
操作系统: Windows 11 23H2
SD 1.5 推理性能 UL Procyon Benchmark
SD1.5是当前最流行的SD基座版本,也是现在模型社区的主要微调训练版本,可在最低 6GB 显存上进行推理运行。
测试参数:
采样器:DDIMScheduler
生图分辨率:512*512
生图步数:100
生图数量:16
batch_size:4
SD 1.5 推理性能吐司测试(TensorRT启用前后对比)
采样器:DPM++ 2M
生图分辨率:512*512
生图步数:50
生图数量:20
batch_size:1
根据吐司平台的测试结果,在NVIDIA TensorRT的加持下,英伟达RTX40系显卡可以实现最高翻倍的生图性能提升。
SDXL 推理性能 UL Procyon Benchmark
采样器:DDIMScheduler
生图分辨率:1024*1024
生图步数:100
生图数量:16
batch_size:1
SDXL模型推理需要至少10GB显存,故 RTX 4060 8GB 因显存不足无法完成测试。
SDXL 推理性能吐司测试(TensorRT启用前后对比)
采样器:DPM++ 2M
生图分辨率:1024*1024
生图步数:50
生图数量:20
batch_size:1
在SDXL生图任务上,也几乎都能达到50%以上的性能提升
NVIDIA RTX AIPC 在 Stable Diffusion 图像生成任务上的表现
AIPC的SD图像生成能力测试中,我们测试了搭载 GeForce RTX 4050 - RTX 4090 笔记本电脑 GPU 的 ASUS华硕 / ROG 的 RTX AIPC。
SD 1.5 推理性能 UL Procyon Benchmark
SD1.5 推理性能吐司测试(TensorRT启用前后对比)
SDXL 推理性能 UL Procyon Benchmark
SDXL模型推理需要至少10GB显存,故 RTX 4050 Laptop, RTX 4060 Laptop, RTX 4070 Laptop 因显存不足无法完成测试。
SDXL 推理性能吐司测试(TensorRT启用前后对比)
NVIDIA RTX 40 系列 Laptop GPU在笔记本上依旧有亮眼的表现,且兼具便携、低功耗等特点,更适合有通勤需求的用户
NVIDIA RTX AIPC 对比 Intel Arc Graphics
测试工具:UL Procyon Benchmark
采样器:DDIMScheduler
生图分辨率:512*512
生图步数:100
生图数量:16
batch_size:4
对比硬件型号:
- RTX 4090 Laptop GPU
- Intel Core Ultra 9 185H
图像生成任务所需的硬件配置总结
| 模型 | 参数量 | 独立显卡 | AIPC |
|---|---|---|---|
| SD 1.5 | 9亿 | 最低:GeForce RTX 4060 8GB推荐:GeForce RTX 4070 12GB 及以上 | 最低:RTX 4050 Laptop 6GB推荐:RTX 4080 Laptop 12GB 及以上 |
| SDXL 1.0 | 35亿 | 最低:GeForce RTX 4070 12GB推荐:GeForce RTX 4070 SUPER 12GB 及以上 | 最低:RTX 4080 Laptop 12GB推荐:RTX 4090 Laptop 16GB |
模型微调训练任务的硬件性能测试
NVIDIA RTX 显卡 在 SD 1.5 LoRA训练任务的测试
底模:Anything V5
LoRA rank: 32
分辨率:512*512
样本量:1000
Batch size: 4
NVIDIA RTX 显卡 在 SDXL LoRA训练任务的测试
在模型微调任务中,CPU性能、显存和算力都有可能成为瓶颈。
由于SDXL LoRA训练需要至少10GB的显存,RTX 4060 8GB 因显存不足而无法进行 SDXL LoRA训练,12GB显存及以下的显卡无法完成batch_size=4的测试,16GB显存及以下的显卡无法完成batch_size=8的测试。
RTX 4090 D拥有高达24GB的显存和14592个CUDA核心,在计算密集型任务上有额外优势,所以本次吐司在SDXL微调任务上将batch size提升到了8,将RTX 4090 D的性能发挥到极致,训练效率也相比batch size=1时提升了将近100%
底模:Anything XL
LoRA rank: 32
分辨率:1024*1024
样本量: 1000
NVIDIA RTX AIPC 在 SD 1.5 LoRA 训练任务的测试
由于SD1.5 LoRA训练需要至少8GB的显存,RTX 4050 Laptop 因显存不足而无法进行SD1.5 LoRA训练。
NVIDIA RTX AIPC 在 SDXL LoRA训练任务的测试
由于SDXL LoRA训练需要至少10GB的显存,RTX 4050 Laptop, RTX 4060 Laptop, RTX 4070 Laptop 因显存不足而无法进行SDXL LoRA训练。
模型微调训练所需的硬件配置总结
| 模型 | 参数量 | 独立显卡 | AIPC |
|---|---|---|---|
| SD 1.5 | 9亿 | GeForce RTX 4070 12GB | RTX 4060 Laptop 8GB |
| SDXL 1.0 | 35亿 | GeForce RTX 4070Ti SUPER 16G | RTX 4090 Laptop 16GB |
结语
人工智能技术曾经一度是大中型企业的私有工具,有着极高的学习与应用门槛。但在过去的一年中,随着StableDiffusion等生成式AI应用的火爆,我们欣喜地发现,我们已经能在每一台个人电脑上部署生成式AI模型,每一个用户都能够根据自己的喜好,微调出属于自己的大模型。我们衷心地期待,随着大模型技术和硬件加速器的蓬勃发展,AI大模型可以成为每个人的生产力工具,能够为每个人的工作和娱乐定义新的范式。
附录
测试显卡型号一览
感谢英伟达、影驰、七彩虹公司为我们提供测试显卡:
- 七彩虹 iGame GeForce RTX 4090 D Advanced 24GB
- GeForce RTX 4080 SUPER 16GB Founders Edition
- GeForce RTX 4080 16GB Founders Edition
- 影驰 GeForce RTX 4070Ti SUPER 大将 OC 16GB
- GeForce RTX 4070Ti 12GB Founders Edition
- GeForce RTX 4070 SUPER 12GB Founders Edition
- GeForce RTX 4070 12GB Founders Edition
- 七彩虹 iGame GeForce RTX 4060Ti 16GB
- GeForce RTX 4060 8GB Founders Edition
测试AIPC型号一览
感谢华硕公司为我们提供测试AIPC:
- RTX 4090 Laptop 16GB ROG 枪神8 Plus 超竞版
- RTX 4080 Laptop 12GB ROG 魔霸7 Plus超能版
- RTX 4070 Laptop 8GB ROG 枪神8
- RTX 4060 Laptop 8GB ROG 魔霸新锐2024
- RTX 4050 Laptop 6GB 华硕天选4锐龙版